Ever dreamt of predicting the perfect bracket or calling that buzzer-beater win? Buckle up, because we’re about to delve into the exciting world of using machine learning to forecast NBA game winners.
Just like in e-commerce, where similar products need to be identified despite variations in names and descriptions, predicting NBA game outcomes involves understanding complex patterns and relationships between teams, players, and historical data. Here at Todaha, we’ve been working on a cutting-edge model that analyzes this data to forecast victories with surprising accuracy.
The Game Plan: Data Acquisition and Feature Engineering
Our journey begins with gathering historical NBA game data. We use libraries like requests and nba_api.stats.endpoints to scrape details like team matchups, win/loss records, and player statistics. This data becomes the foundation for our predictions.
But raw data isn’t enough. We then transform it into a format suitable for machine learning algorithms. This involves cleaning the data, handling missing values, and calculating various features that might influence game outcomes. Here are some key features we consider:
- Team Statistics: We analyze performance metrics like field goal percentage, free throw percentage, rebounds, assists, turnovers, steals, blocks, and points per game for both teams leading up to the game date (e.g., past 14 days).
Short Literature Survey: A Look at the Players on the Court (Machine Learning Models)
Before diving into our specific approach, let’s take a quick timeout to explore some of the machine learning models commonly used for prediction tasks:
- Siamese Networks: Imagine twins on the court, working in perfect sync. These networks consist of two identical sub-networks that learn to compare two data points (like two teams) and output a similarity score. The closer the score is to 1, the more similar the teams are predicted to be in terms of performance.
- Triplet Networks: Think of this as having three players on the court: an anchor team, a similar team (positive image), and a dissimilar team (negative image). The network learns to distinguish between these teams, ensuring the positive team is a closer “match” to the anchor team than the negative one.
- Convolutional Neural Networks (CNNs): These are the all-stars of image recognition, but they can also be used for analyzing data like team statistics. By mimicking the human brain’s visual processing capabilities, CNNs can extract complex patterns from the data and use them for prediction.
- Random Forests: Imagine a forest of decision trees, each one making its own prediction based on a specific set of features. The final prediction is based on the majority vote from all the trees, offering a robust and interpretable approach.
These are just a few of the many models used in the world of sports analytics. Choosing the right model depends on the specific problem and the type of data available.
Choosing Our Weapon: Deep Learning Models
Now comes the exciting part: selecting the right model architecture for our NBA prediction challenge. We explore two promising options:
- Deep Neural Network (DNN): This workhorse of deep learning consists of multiple hidden layers that learn complex patterns from the data. We build a custom
Netclass inheriting fromnn.Moduleto define our DNN architecture. - Genetic Algorithm (GA): Inspired by evolution, a GA iteratively improves a population of models. It selects the best performers for breeding and introduces mutations to explore different possibilities. This allows us to potentially discover an optimal model structure, like a team constantly adapting its plays to counter different opponents.
Both the DNN and GA are trained on a portion of the data, constantly adjusting their parameters to minimize prediction errors. The remaining data is used for evaluation, where we assess how well the models perform on unseen games.
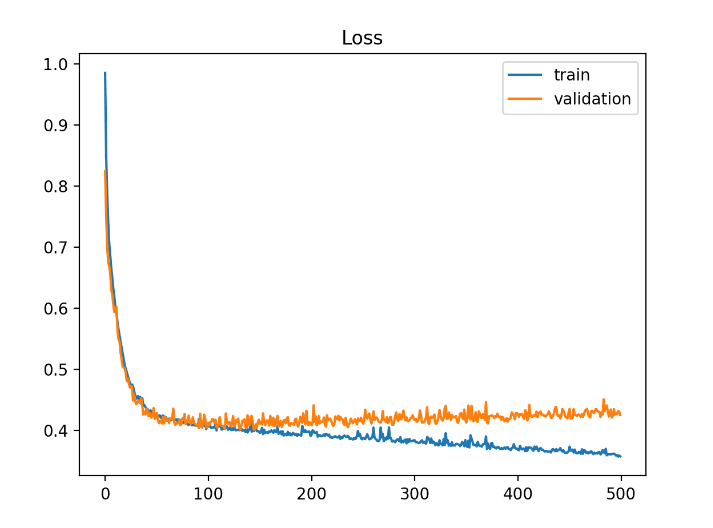
Seeing the Shots Go In: Evaluation and Results
Our initial results are promising! Both the DNN and GA approaches achieve an accuracy of around 68-70% in predicting the winning team. While this may not guarantee you a perfect bracket every season, it demonstrates the potential of machine learning in analyzing NBA games. Here’s a graph to visualize these results:
Beyond the Buzzer: Limitations and Future Directions
It’s important to acknowledge the limitations of our model. Predicting NBA games is complex, and factors like injuries, trades, and unexpected player performances can’t be easily accounted for with historical data. Additionally, ethical considerations arise when such models are used for sports betting, as they could potentially influence game outcomes.
However, this is just the first quarter. Here’s what lies ahead:
- Incorporating More Features: We can explore additional features like player injuries, team coaching styles, and historical matchups between specific teams. This would be like adding new plays and strategies to our model’s playbook.
- Enhancing Model Complexity: Experimenting with more sophisticated model architectures like recurrent neural networks (RNNs) could capture temporal dynamics within a season. RNNs can learn from past games and potentially predict how a team’s performance might evolve throughout the season.
- Data, Glorious Data: As we gather more historical data and potentially even incorporate real-time game statistics, the model’s accuracy is likely to improve. This is like having a constantly growing scouting report that allows the model to adapt and make even more accurate predictions.
By continuously developing our model, we hope to provide valuable insights not just for predicting winners, but also for analyzing team trends, scouting players, and making informed decisions in the exciting world of basketball. The future of NBA analytics is bright, and machine learning is poised to play a key role in making the game even more strategic and exciting for fans and analysts alike.